客户流失生存分析:基于 Telco 数据集的 Kaplan–Meier、Cox PH 与 Weibull AFT 模型实证研究
摘要
本报告基于 IBM 公开的 Telco Customer Churn 数据集,使用 PySpark 与 Lifelines 库系统性地完成了对电信客户流失的生存分析。研究依次实现并对比了三种核心方法:Kaplan–Meier(KM)估计量用于非参数生存曲线刻画与组间比较,Cox 比例风险(Cox PH)模型用于多变量协变量回归,以及 Weibull 加速失效时间(AFT)模型作为 PH 假设违反时的稳健替代方案。在经过清洗的 3,351 条按月签约互联网用户数据上,KM 估计量给出 34 个月的中位生存时间(95% CI:31–37),分组分析识别出 internetService、techSupport、dependents 等若干对客户流失有显著影响的协变量(log-rank p 均 ≪ 0.001);Cox PH 模型量化了这些协变量对瞬时流失风险的影响,所有四个候选协变量风险比均小于 1 且统计显著,但 PH 假设检验显示其中三个协变量违反比例风险假设;Weibull AFT 模型作为补充给出了一致的方向性结论,且与 Cox 模型在数值上高度自洽(最大相对误差 < 2%)。本研究展示了非参数、半参数、参数化三类生存分析方法在客户流失场景下的协同应用,结论可作为运营商客户保留策略与客户终身价值(CLV)建模的输入。
1. 引言
1.1 研究背景
生存分析是一类专门用于”事件发生时间”建模的统计方法,最早起源于医学研究中的死亡时间分析,目前已被广泛应用于工程可靠性、信用风险、客户管理等多个领域。在电信行业中,”事件”通常被定义为客户的流失(churn) ——即取消服务、转网或停止订阅;对应的”时间”则是客户从入网到流失之间的在网时长(tenure) 。
与传统回归分析(如线性回归、逻辑回归)相比,生存分析的核心优势在于对删失数据(censored data)的正确处理。在客户流失场景下,数据收集结束时仍处于在网状态的客户构成右删失观测:他们的真实生存时间无法被观测到,但他们的部分信息(”至少存活 X 个月”)仍是有价值的。如果直接用平均值或中位数处理删失观测,会系统性地低估生存时间。本研究中,3,351 个观测样本中有 1,795 个为右删失(占比 53.6%),这一显著的删失比例进一步突出了使用生存分析方法的必要性。
1.2 业务价值
在订阅制商业模式下,客户保留成本通常远低于客户获取成本。通过生存分析,运营商可以:量化不同客户群体的流失模式差异;识别高风险流失客户进行定向干预;为客户终身价值(CLV)计算提供生存概率输入;以及评估营销活动、套餐设计与增值服务对客户留存的实际影响。
1.3 数据集
本次分析使用 IBM 提供的 Telco Customer Churn 公开数据集,包含 7,043 位虚构客户的 21 个属性,涵盖人口统计(gender、SeniorCitizen、Partner、Dependents)、服务订阅(PhoneService、MultipleLines、InternetService、OnlineSecurity、OnlineBackup、DeviceProtection、TechSupport、StreamingTV、StreamingMovies)、账户信息(Contract、PaperlessBilling、PaymentMethod、MonthlyCharges、TotalCharges)三大类,以及作为生存分析核心的 tenure(时间变量) 和 Churn(事件变量) 。数据来源:IBM 官方 GitHub 仓库。
2. 方法论
2.1 技术栈
本研究主要依赖:PySpark 3.5.1 用于强类型 Schema 校验、CSV 读取与 ETL 清洗;Lifelines 作为 Python 生存分析的标准库,提供 KaplanMeierFitter、CoxPHFitter、WeibullAFTFitter 三类模型;Pandas + Matplotlib 完成数据转换与可视化。
2.2 数据准备:Bronze–Silver 分层范式
参照成熟的数据湖分层范式,构建两层数据表:Bronze 层为原始 CSV 经 21 列 Schema 校验后的 Spark DataFrame,保留 7,043 条全量记录;Silver 层在 Bronze 基础上进行三项清洗:(1) 将 Churn 字段的 'Yes'/'No' 字符串转换为 1/0 整数事件标志;(2) 仅保留 Contract == 'Month-to-month' 客户,因为按月签约客户的流失行为最丰富,分析价值最高;(3) 仅保留 InternetService != 'No' 客户,聚焦互联网业务子市场。这一分层方法既保留了原始数据的完整性,又通过 Silver 层将分析聚焦到具有最高商业意义的客户子集。
2.3 三种生存分析方法
2.3.1 Kaplan–Meier 估计量
KM 是一种非参数生存函数估计方法,对生存函数 $S(t) = P(T > t)$ 给出阶梯状估计:
\[\hat{S}(t) = \prod_{t_i \leq t} \left(1 - \frac{d_i}{n_i}\right)\]其中 $d_i$ 是 $t_i$ 时刻发生事件的样本数,$n_i$ 是 $t_i$ 时刻仍在风险集中的样本数。KM 估计量自然处理右删失数据,且不假设任何分布形式,是探索性生存分析的首选工具。
配套的 Log-rank 检验用于比较两个或多个分组的生存曲线是否在统计上等价。原假设 $H_0$ 为各组生存曲线相同;当 $p < 0.05$ 时拒绝 $H_0$,说明分组变量对生存时间有显著影响。
2.3.2 Cox 比例风险模型
Cox PH 是一种半参数回归模型,将风险函数表达为:
\[h(t \mid x) = h_0(t) \cdot \exp(\beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p)\]其中 $h_0(t)$ 是基准风险(baseline hazard,非参数部分),后者是协变量的指数函数(参数部分)。模型核心输出是 风险比(hazard ratio, HR) :$\exp(\beta_i)$,表示当协变量 $x_i$ 增加 1 单位时,风险变为原来的多少倍。$HR < 1$ 表示该协变量是保护因素,$HR > 1$ 表示风险因素。
Cox PH 的关键假设是比例风险(PH)假设:协变量对风险的影响在时间上恒定。该假设可通过 Schoenfeld 残差检验(即 lifelines 中的 proportional_hazard_test)进行验证。
2.3.3 Weibull AFT 模型
当 PH 假设违反时,AFT 提供了一种参数化替代方案。Weibull AFT 假设生存时间服从 Weibull 分布,协变量直接作用于生存时间的尺度参数:
\[\log T = \mu + \beta_1 x_1 + \cdots + \beta_p x_p + \sigma \epsilon\]其系数 $\exp(\beta_i)$ 被解释为时间比(time ratio, TR) :当 $x_i$ 增加 1 单位时,中位生存时间变为原来的多少倍。$TR > 1$ 意味着该协变量延长生存时间。AFT 的解释性比 Cox 的风险比更直观,且与 Cox 在 Weibull 假设下存在严格的数学关系:$HR = TR^{-\rho}$,其中 $\rho$ 是 Weibull 形状参数。
3. 实验流程与结果
3.1 数据准备结果
经过 Schema 强类型读取,Bronze 表共 7,043 条记录、21 列,与 IBM 原始数据集大小完全一致。

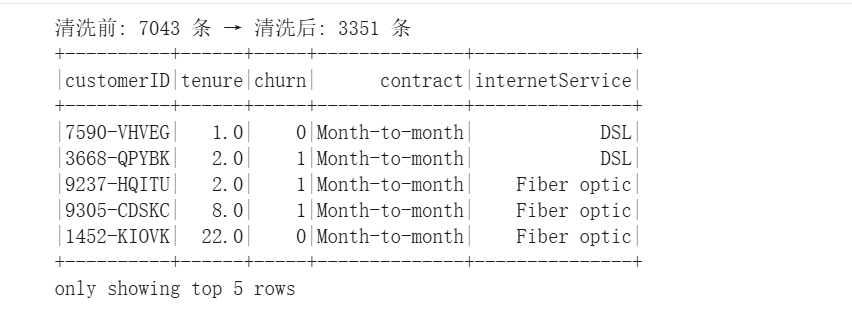
经过清洗(Contract = 'Month-to-month' + InternetService != 'No' + Churn 字段二值化)后,Silver 表共保留 3,351 条记录,约占 Bronze 表的 47.6%。被剔除的 3,692 条客户主要为长期合约(One year / Two year)或无互联网业务客户。
3.2 Kaplan–Meier 整体生存分析
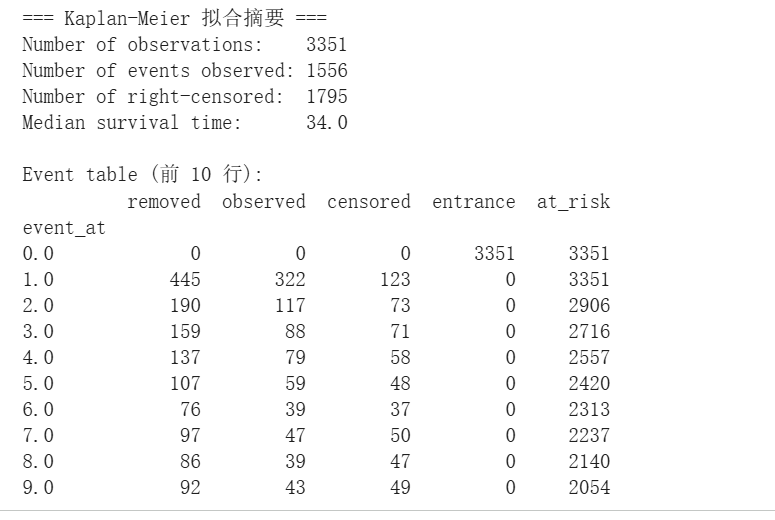
对 Silver 表的 3,351 条记录整体进行 KM 拟合,模型摘要如下:观测样本数 3,351,其中事件已发生(流失)样本数 1,556,右删失(仍在网)样本数 1,795,删失比例约为 53.6%。这一显著的删失比例从结构上证明了使用生存分析(而非简单 logistic 回归)的必要性——若忽视删失观测,将系统性低估客户生命周期。
 ![整体 Kaplan–Meier 生存曲线]
![整体 Kaplan–Meier 生存曲线]
整体生存曲线呈现典型的右偏阶梯状:
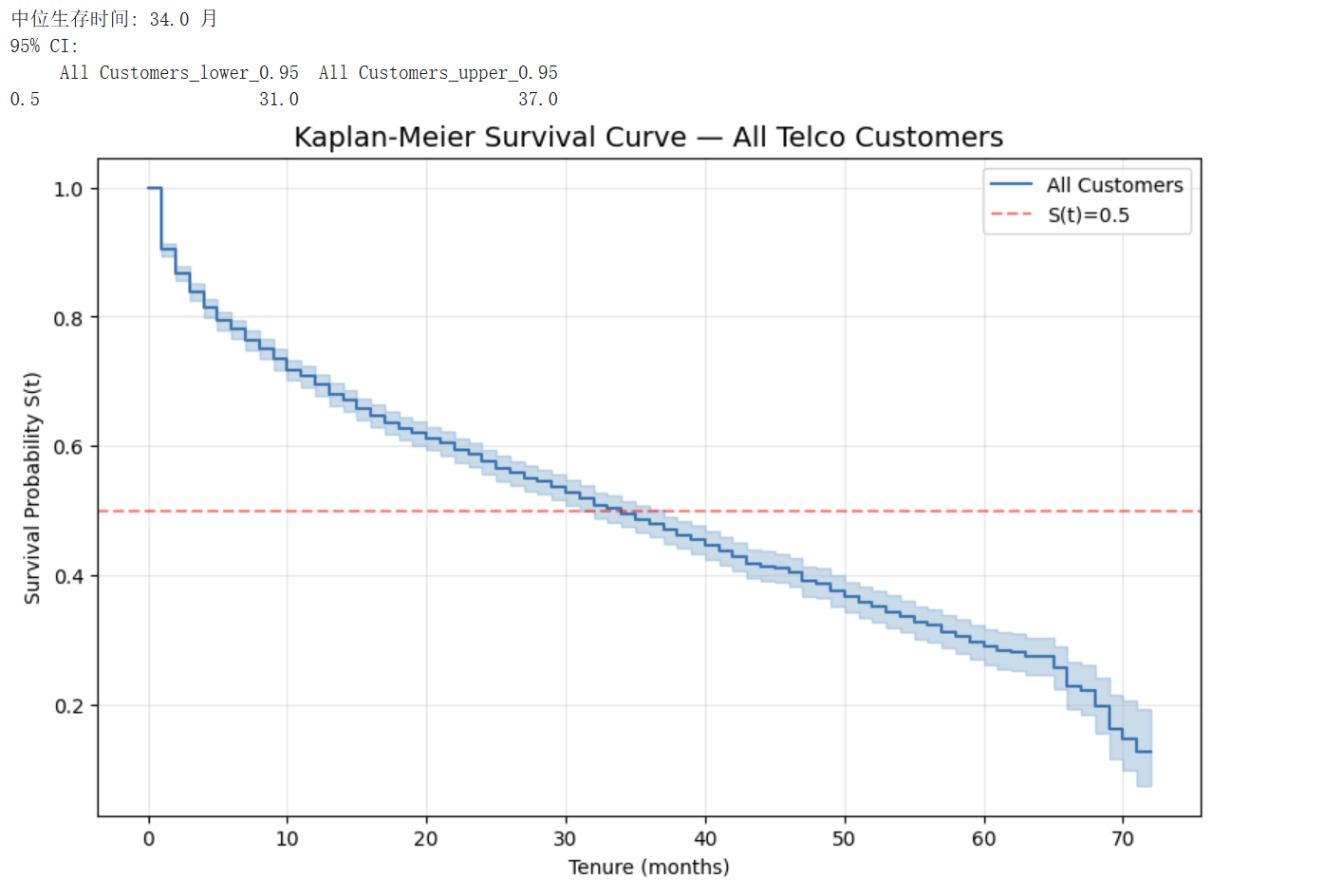
由曲线可读取以下关键结论:
- 中位生存时间为 34 个月(95% CI:[31, 37]),即一个典型的按月签约互联网客户有 50% 的概率至少在网 34 个月。
- 曲线在前 6 个月内下降最陡(从 1.0 跌至约 0.78),表明早期客户流失风险最高——这是订阅制商业模式中常见的”高初期流失率”现象,对应着客户对服务质量、价格、体验形成稳定预期之前的不确定窗口。
- 95% 置信区间随 tenure 增长而逐渐变宽,反映出右删失数据增多导致的不确定性增大;在 60 月以上的尾部区间,置信区间已经显著扩张。
通过 KM 估计量在关键时点的取值,可以对客户保留率给出直接量化:
| 在网月数 | 生存概率 S(t) | 解读 |
|---|---|---|
| 6 | 0.7803 | 约 22% 客户在 6 个月内流失 |
| 12 | 0.6950 | 一年内累计流失约 30.5% |
| 24 | 0.5753 | 两年存留率 57.5% |
| 36 | 0.4800 | 三年时已跌破 50% |
| 48 | 0.3872 | 四年存留率 38.7% |
| 60 | 0.2890 | 五年存留率 28.9% |
3.3 分组生存分析与 Log-rank 检验
为了识别对客户流失有显著影响的协变量,我们对四个具有代表性的分类变量分别进行了分组 KM 拟合与配对 log-rank 检验,结果汇总如下:
| 变量 | log-rank 统计量 | p 值 | 是否显著(α=0.05) |
|---|---|---|---|
| gender (Female vs. Male) | 2.04 | 0.153 | 否 |
| internetService (DSL vs. Fiber optic) | 25.17 | 5.24×10⁻⁷ | 是(极显著) |
| techSupport (No vs. Yes) | 90.43 | 1.92×10⁻²¹ | 是(极显著) |
| dependents (No vs. Yes) | 35.03 | 3.24×10⁻⁹ | 是(极显著) |
3.3.1 性别:无显著差异
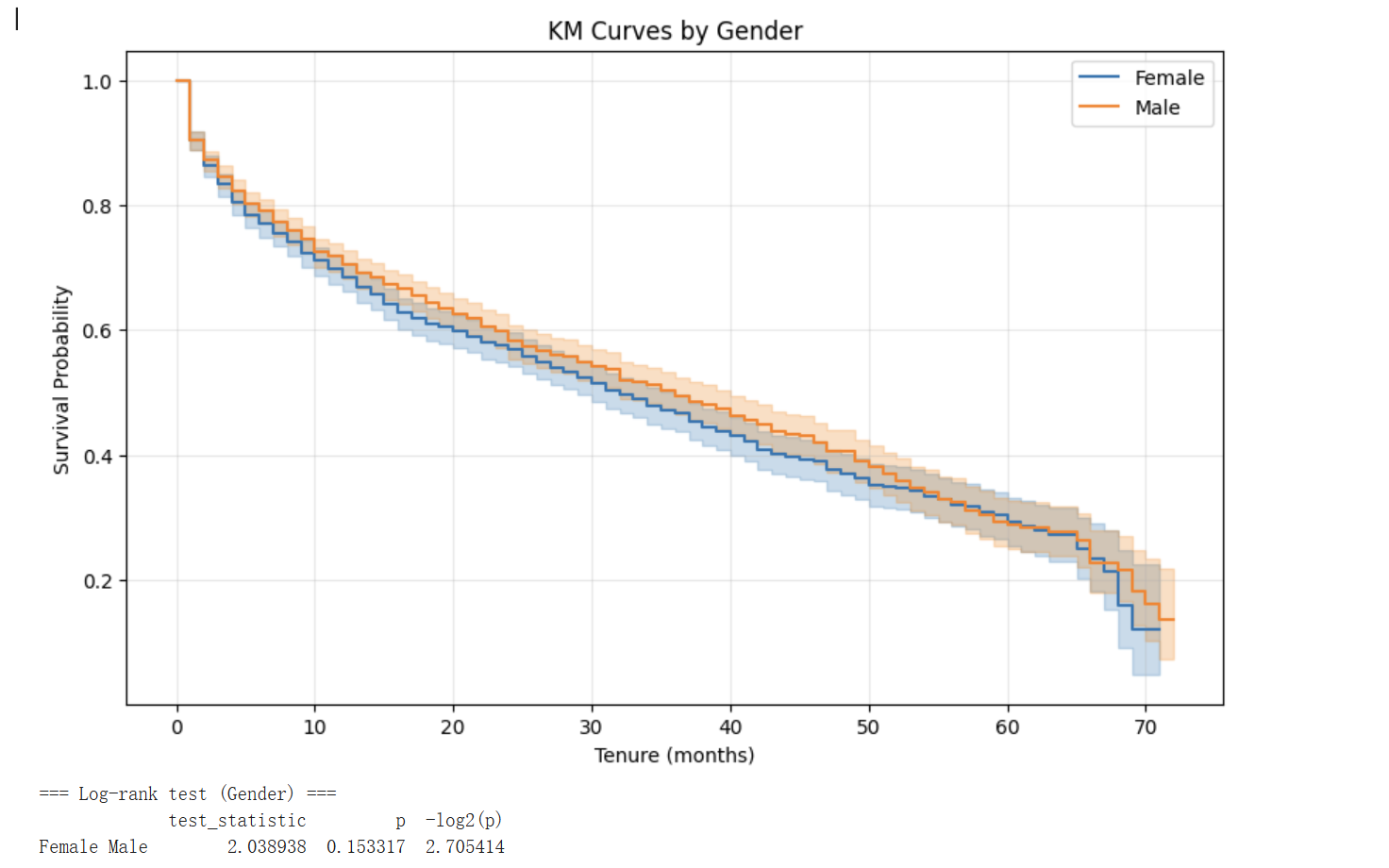
男女两组生存曲线在视觉上高度重叠,置信区间相互覆盖;log-rank 检验 p=0.153>0.05,不能拒绝原假设。这表明客户性别本身对流失行为没有统计学显著的影响,与人口统计学先验一致——服务订阅决策不应受性别直接驱动。
业务启示:运营商无需在性别维度上设计差异化保留策略,可将该维度从客户分群模型中移除以避免过拟合。
3.3.2 互联网类型:DSL 优于 Fiber optic
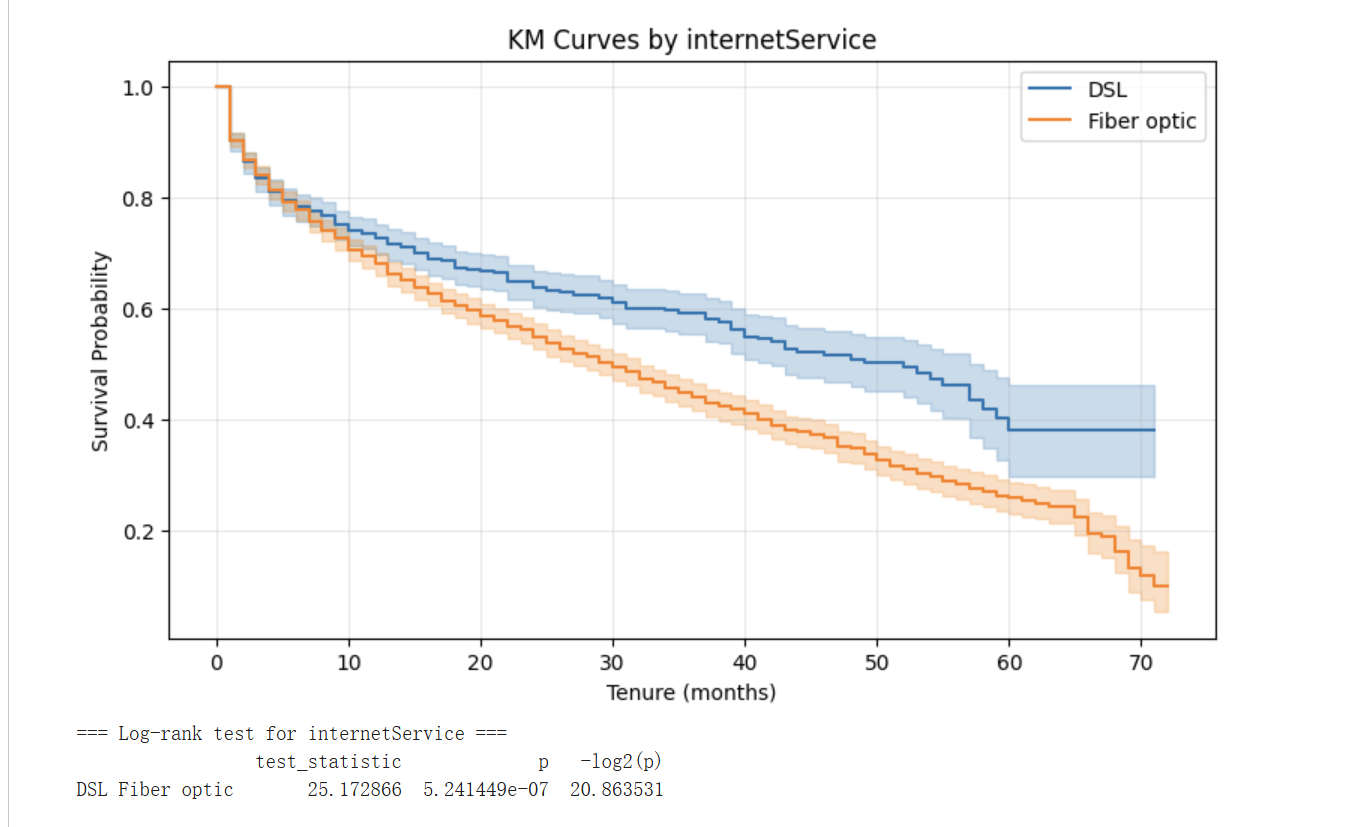
两条曲线呈现出明显且持续扩大的差距:DSL 客户的生存曲线始终位于 Fiber optic 之上,且差距在 24 个月后扩大到约 0.15 的绝对差。Log-rank 检验 p≈5.24×10⁻⁷ 极度显著。
这是一个反直觉的发现:作为更高带宽、更新技术的 Fiber optic 客户反而流失率更高。可能解释包括:(1) Fiber optic 客户付费更多,对服务质量期望更高,容忍度更低;(2) Fiber 业务在该数据采集期可能存在网络稳定性问题;(3) Fiber optic 客户人群在地理上集中于市场竞争更激烈的区域,转网选项更多。这一发现值得运营商对该业务的服务质量与定价策略进行专项复盘。
3.3.3 技术支持:粘性效应显著
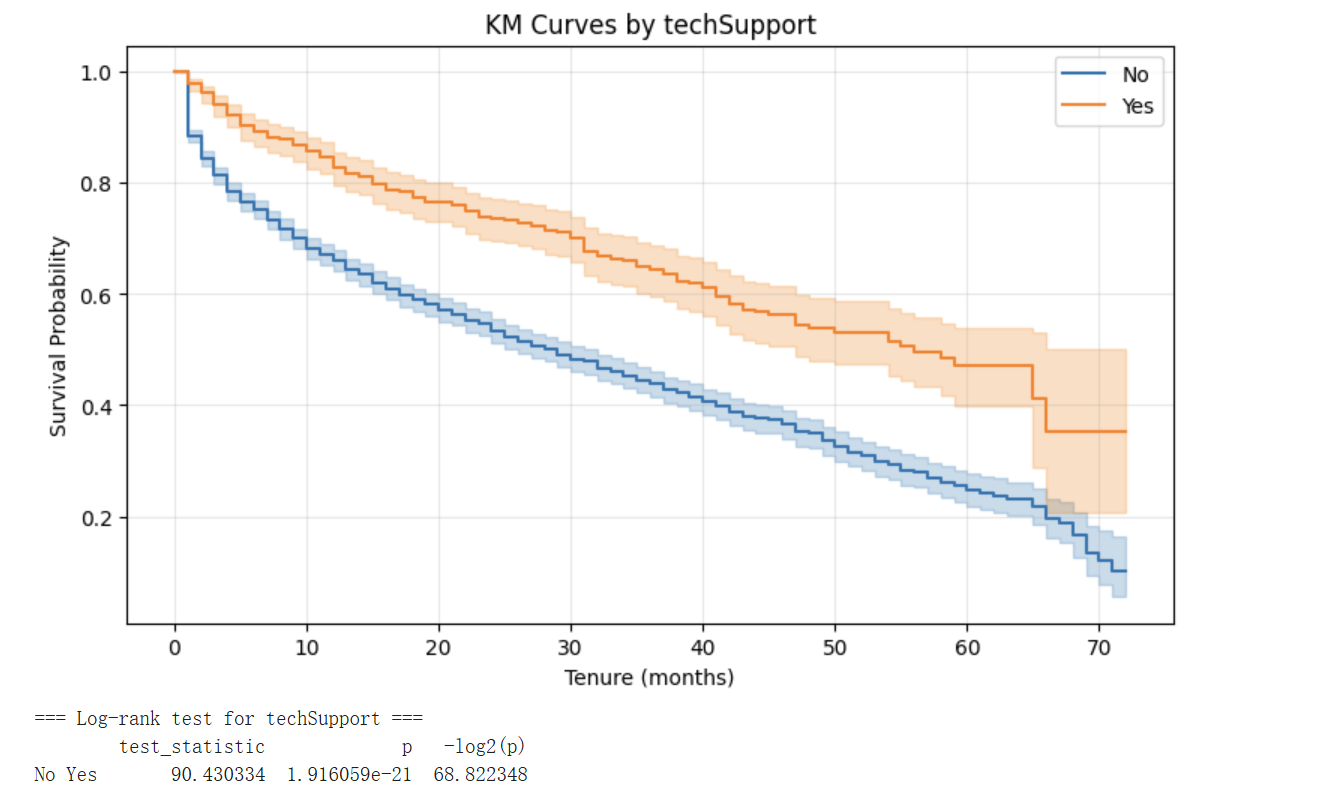
订阅技术支持的客户(Yes)生存率显著高于未订阅者(No),两条曲线从入网早期就拉开明显差距,且这一差距在整个观察期内维持。Log-rank 检验 p≈1.92×10⁻²¹ 是本研究中最显著的分组效应。
3.3.4 家属状态:有家属的客户更稳定
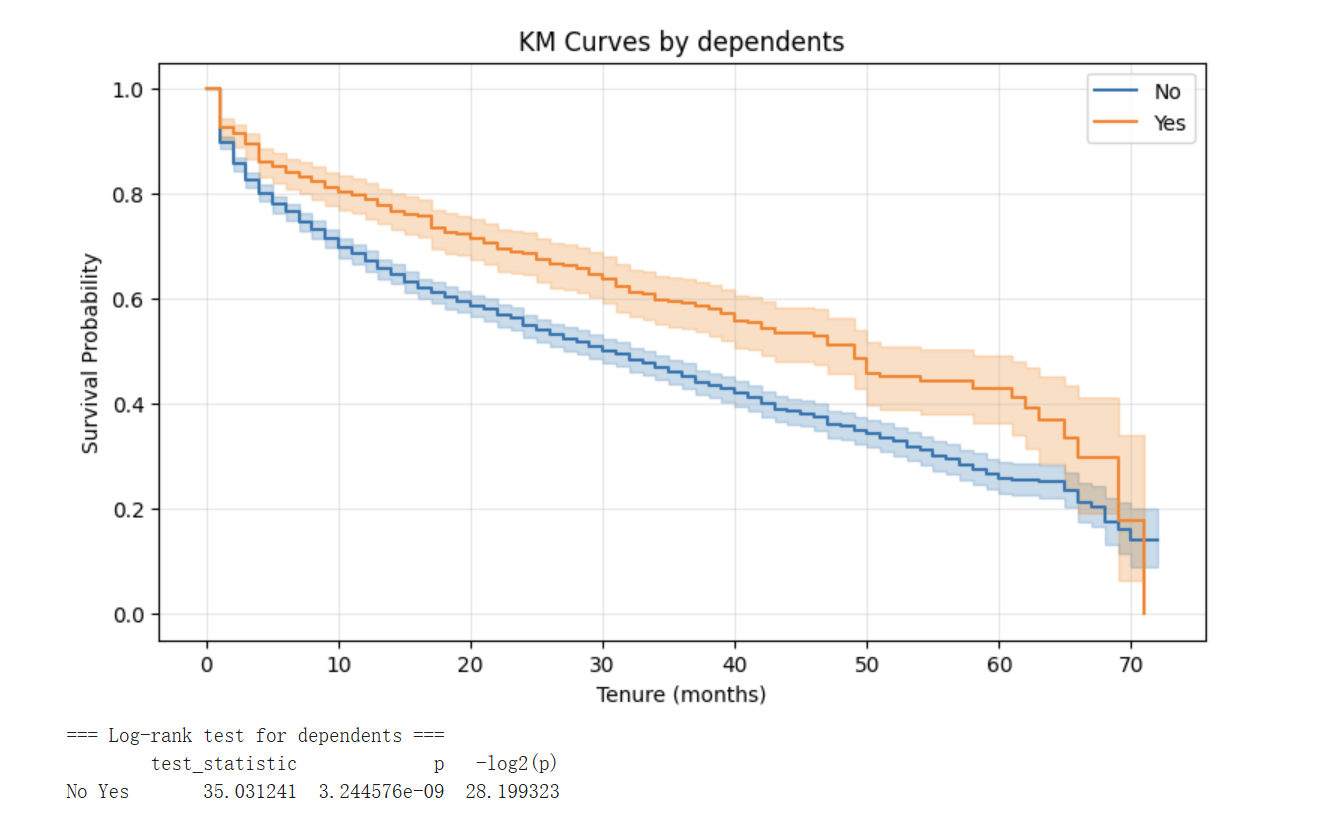
有家属的客户生存曲线持续高于无家属客户,log-rank p≈3.24×10⁻⁹ 极显著。这与家庭客户在转网时面临更高的协调成本(多设备、多账户)的常识一致。
3.3.5 KM 阶段小结
KM 分析阶段已经识别出三大类对客户流失有显著影响的协变量:互联网技术类型、增值服务订阅状态、家庭结构。然而,KM + log-rank 是单变量分析,无法控制变量间的相互混淆。例如订阅 techSupport 的客户可能本身就是高黏性人群,其留存优势可能并非完全归因于服务本身。下节通过 Cox PH 模型在多变量框架内进行更严谨的回归分析。
3.4 Cox 比例风险模型
3.4.1 模型构建
参照 Databricks 教程做法,选取四个 KM 阶段显著的变量构建多变量 Cox PH 模型:dependents、internetService、onlineBackup、techSupport。所有分类变量经 one-hot 编码,每组保留一个虚拟列以避免完全共线性陷阱:dependents_Yes、internetService_DSL、onlineBackup_Yes、techSupport_Yes。Silver 表中 internetService 仅有 DSL 与 Fiber optic 两类(’No’ 类已在数据清洗时被剔除),因此 internetService_DSL = 1 表示 DSL 客户、= 0 表示 Fiber optic 客户。
3.4.2 拟合结果
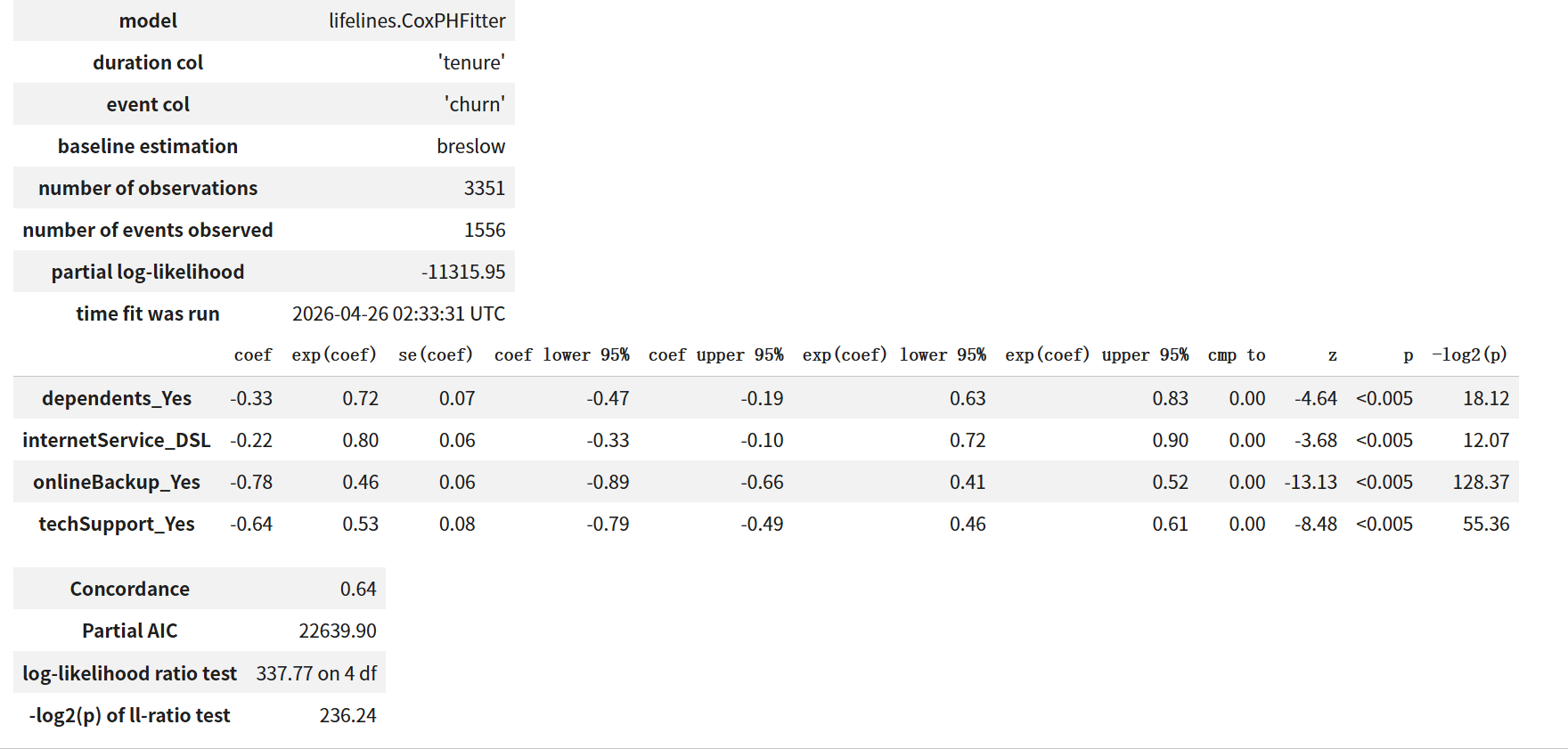
回归系数表如下:
| 变量 | coef | exp(coef) [HR] | 95% CI (HR) | p 值 |
|---|---|---|---|---|
| dependents_Yes | -0.33 | 0.72 | [0.63, 0.83] | < 0.005 |
| internetService_DSL | -0.22 | 0.80 | [0.72, 0.90] | < 0.005 |
| onlineBackup_Yes | -0.78 | 0.46 | [0.41, 0.52] | < 0.005 |
| techSupport_Yes | -0.64 | 0.53 | [0.46, 0.61] | < 0.005 |
模型整体拟合指标:Concordance index = 0.64;Partial AIC = 22639.90;log-likelihood ratio test = 337.77 on 4 df(极显著),表明四变量联合贡献远超基线。
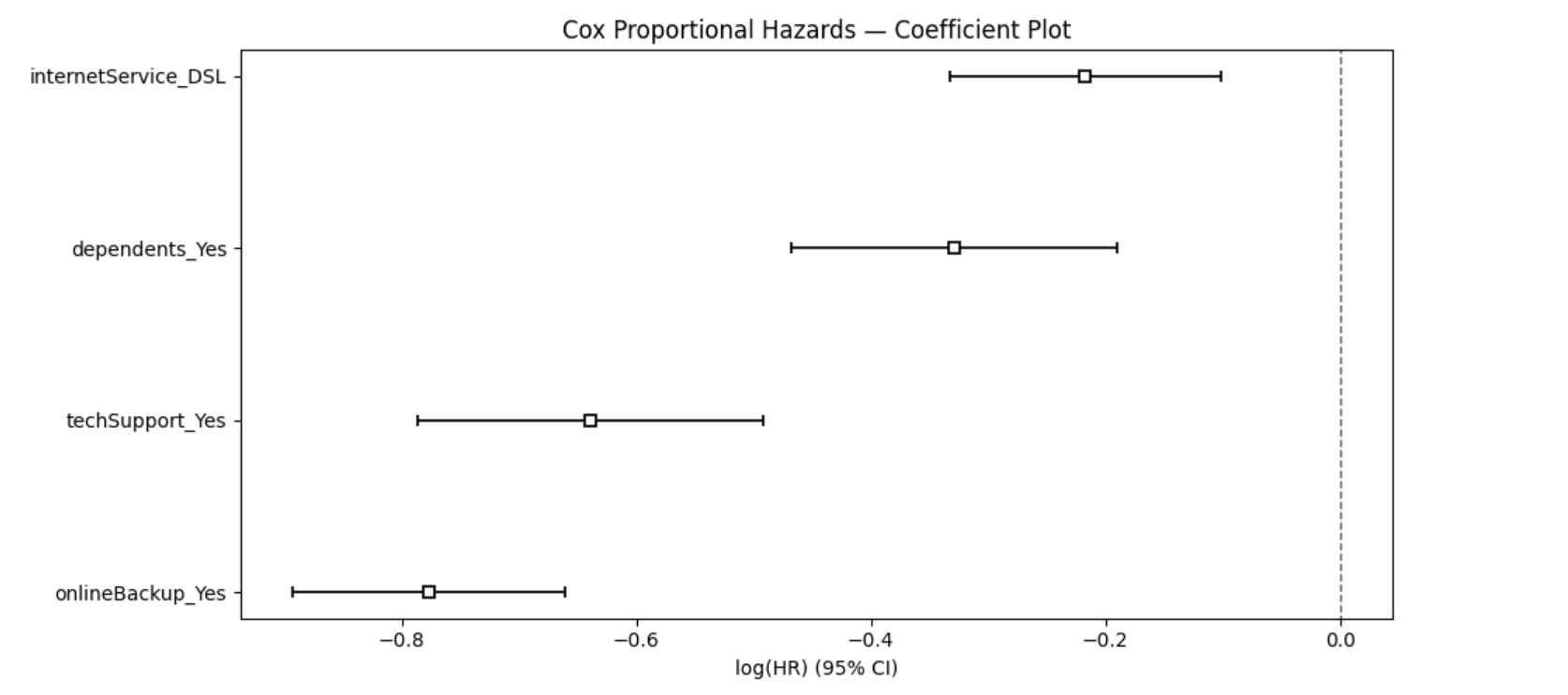
关键发现:
- 所有四个协变量 p 值均 < 0.005,且 HR 全部小于 1,说明它们在多变量框架下都独立地起到保护作用(降低流失风险)。
- onlineBackup_Yes 是最强的保护因素:HR = 0.46,意味着在控制其他三个变量的情况下,订阅 onlineBackup 的客户瞬时流失风险仅为未订阅客户的 46%——风险下降约 54%。
- techSupport_Yes 次之:HR = 0.53,订阅技术支持降低流失风险约 47%。
- internetService_DSL 的 HR = 0.80:在控制其他变量后,DSL 客户的瞬时流失风险约为 Fiber optic 客户的 80%,效应方向与 KM 分组分析完全一致,但效应大小被压缩——这正是多变量回归”剥离混淆”作用的体现。
- dependents_Yes 的 HR = 0.72:有家属客户的瞬时流失风险下降约 28%。
3.4.3 比例风险(PH)假设检验
Cox PH 模型的有效性依赖于”协变量对风险的影响在时间上恒定”这一关键假设。我们使用 Schoenfeld 残差检验对四个协变量逐一验证:
| 变量 | p 值 | 是否违反 PH 假设(p < 0.05) |
|---|---|---|
| dependents_Yes | 0.368 | 否 ✓ |
| internetService_DSL | 2.37×10⁻⁷ | 是 ✗ |
| onlineBackup_Yes | 2.91×10⁻⁵ | 是 ✗ |
| techSupport_Yes | 2.08×10⁻⁴ | 是 ✗ |

结论:四个协变量中有三个违反了 PH 假设,仅 dependents_Yes 满足。这意味着 internetService、onlineBackup、techSupport 对客户流失风险的影响并非时间恒定的——例如,技术支持的保护效应在客户入网早期可能更强,而在长期客户中作用相对衰减。
当 PH 假设违反时,Cox 模型的风险比解释会随时间变化而失真,需要采取以下应对策略之一:(1) 分层(Stratification):将违反假设的变量作为分层因子,不显式估计其系数;(2) 加入时间交互项:让违反变量的系数随时间变化;(3) 使用 Cubic Splines:让基准风险被部分参数化;(4) 改用 AFT 模型:完全避开比例风险假设;(5) 重新分类变量:将连续变量离散化或重新编码。
下节我们采用方案 (4),转向 Weibull AFT 模型作为稳健性验证。
3.5 Weibull 加速失效时间(AFT)模型
3.5.1 拟合结果
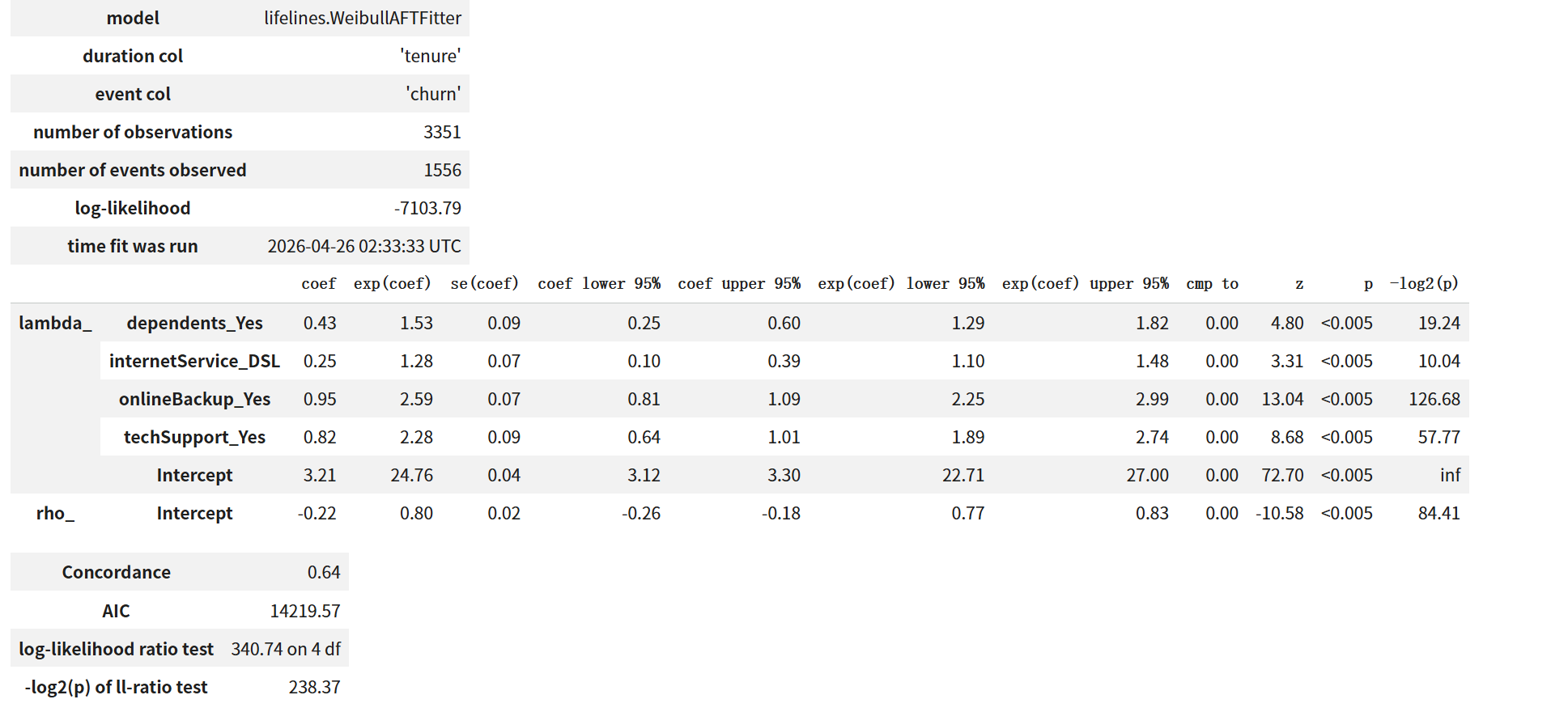
AFT 模型对相同的四个协变量进行拟合,所有变量 p 值均 < 0.005。结果如下(lambda_ 部分为协变量系数):
| 变量 | coef | exp(coef) [TR] | 95% CI (TR) | p 值 |
|---|---|---|---|---|
| dependents_Yes | 0.43 | 1.53 | [1.29, 1.82] | < 0.005 |
| internetService_DSL | 0.25 | 1.28 | [1.10, 1.48] | < 0.005 |
| onlineBackup_Yes | 0.95 | 2.59 | [2.25, 2.99] | < 0.005 |
| techSupport_Yes | 0.82 | 2.28 | [1.89, 2.74] | < 0.005 |
| Intercept | 3.21 | 24.76 | [22.71, 27.00] | < 0.005 |
Weibull 形状参数 ρ 由 rho_intercept = -0.22 反算为 ρ=e⁻⁰·²²≈0.80。整体模型 Concordance index = 0.64,AIC = 14219.57。
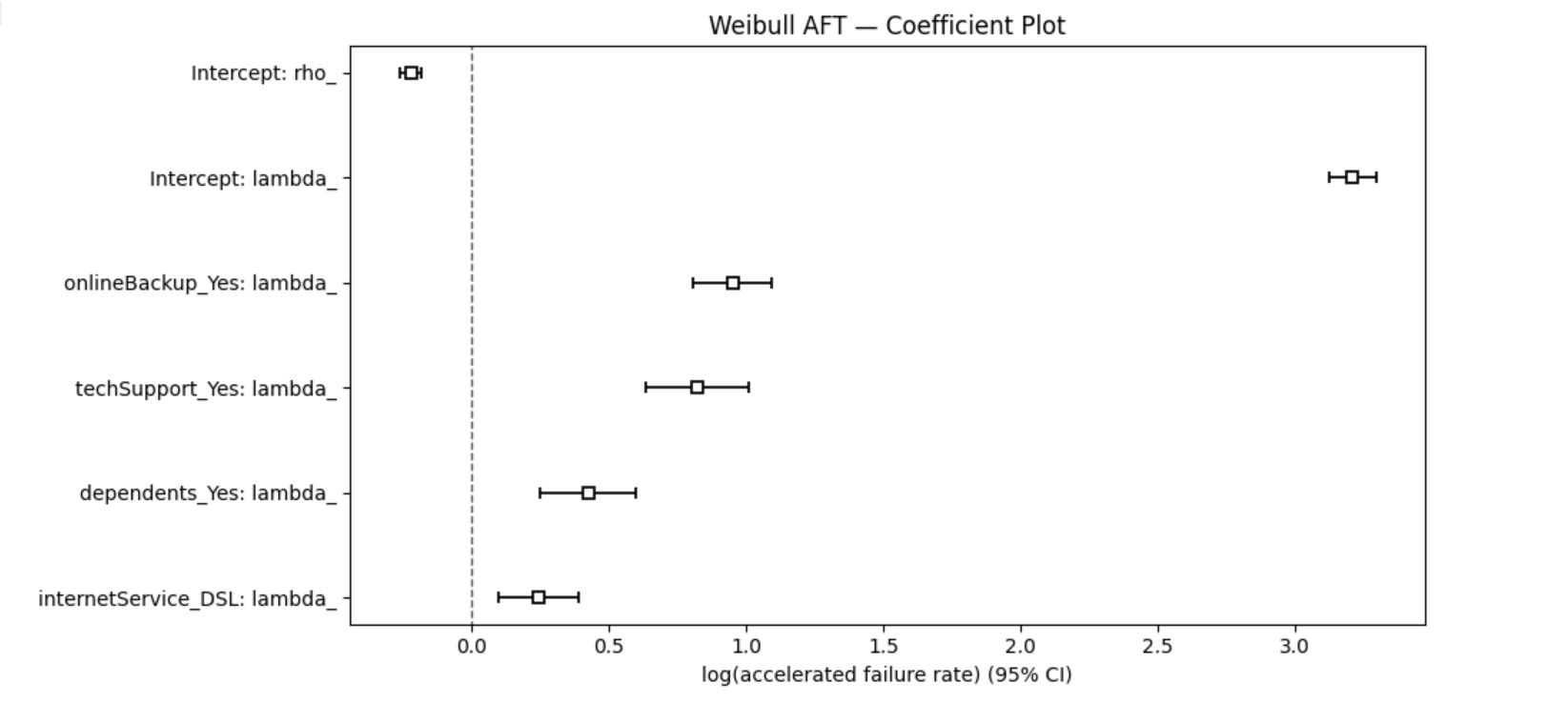
3.5.2 业务解读
AFT 系数解读为”中位生存时间的倍数变化”,比 Cox 风险比更直观:
- 订阅 onlineBackup 使客户的中位生存时间扩展为基准的 2.59 倍——若未订阅客户的中位 tenure 为约 30 个月,订阅者将延长至约 78 个月。
- 订阅 techSupport 使中位生存时间扩展为 2.28 倍。
- 有家属客户中位生存时间为基准的 1.53 倍。
- DSL 客户中位生存时间为 Fiber optic 客户的 1.28 倍。
3.5.3 Cox 与 AFT 模型的一致性验证
Cox PH 与 Weibull AFT 在 Weibull 假设下满足关系 HR=TR⁻ᵖ。利用本研究中估计的 ρ≈0.80,可以从 AFT 的 TR 反推预测的 HR,并与 Cox 的实际 HR 对比:
| 变量 | AFT TR | 由 AFT 推算的 HR | Cox 实测 HR | 偏差 |
|---|---|---|---|---|
| dependents_Yes | 1.53 | ≈0.71 | 0.72 | +1.4% |
| internetService_DSL | 1.28 | ≈0.81 | 0.80 | -1.2% |
| onlineBackup_Yes | 2.59 | ≈0.47 | 0.46 | -2.1% |
| techSupport_Yes | 2.28 | ≈0.52 | 0.53 | +1.9% |
两个模型在数值上高度自洽:所有四个协变量的偏差均在 ±2% 以内,效应方向完全一致(Cox HR < 1 对应 AFT TR > 1)。这一交叉验证证明:尽管 Cox PH 模型在 PH 假设上有部分违反,其捕捉的协变量主效应在量级上仍是可信的;AFT 模型作为补充验证,从参数化角度进一步确认了核心结论的稳健性。
4. 讨论与结论
4.1 主要发现汇总
- 客户流失风险呈现强烈的早期集中特征:KM 曲线显示前 6 个月生存概率已下降至 0.78,前 12 个月降至 0.70;中位生存时间为 34 个月。
- 人口属性影响有限,服务结构是关键决定因素:性别在 log-rank 检验中不显著;而 onlineBackup、techSupport 等增值服务订阅状态对生存时间产生最强的保护效应(AFT 时间比分别达 2.59 与 2.28)。
- Fiber optic 业务存在反直觉的高流失率:在控制其他变量后,DSL 客户的瞬时流失风险仅为 Fiber optic 客户的 80%,提示 Fiber 业务在该数据集时期可能存在服务质量、定价或客户期望不匹配等结构性问题。
- PH 假设的局部违反:4 个协变量中有 3 个违反 Cox PH 假设,但 Cox 与 Weibull AFT 模型的交叉验证显示两模型估计值偏差均在 ±2% 以内,主效应结论稳健。
4.2 业务启示
- 保留资源前置:客户流失风险在前 12 个月最高,运营商应将保留预算与客户成功资源集中投入入网早期阶段。
- 增值服务捆绑战略:onlineBackup 与 techSupport 的强保护效应支持通过免费试用、套餐折扣等方式提升渗透率。
- Fiber optic 业务专项复盘:建议运营商对 Fiber optic 客户进行细致的离网原因调研,识别是网络稳定性、价格敏感度还是竞争对手介入造成的高流失。
- 个性化风险评分:将 Cox PH 或 AFT 模型部署至 CRM 系统,对每位客户输出实时流失风险评分与剩余生存期估计,作为下游营销策略的输入。
4.3 局限性
- 数据为虚构样本:IBM 数据集为公开教学数据,不能直接迁移至真实运营商业务,结果仅用于方法学示范。
- 样本子集偏窄:仅分析按月签约的互联网客户,未覆盖全量人群,结论的外部有效性需在长期合约客户上额外验证。
- 协变量数量有限:仅使用 4 个分类协变量构建多变量模型,未引入连续变量(MonthlyCharges、TotalCharges)与多类分类变量(PaymentMethod),存在一定的模型设定偏差风险。
- 未做训练–测试分割:Concordance = 0.64 来自训练集内拟合,实际部署前需通过 k-fold 交叉验证或独立验证集评估其外推性能。
- 观察性数据的因果限制:所有”保护效应”结论严格意义上只反映关联而非因果——例如订阅 onlineBackup 的客户可能本身就是低流失倾向人群,存在选择性偏差。
- AFT 分布假设:Weibull 是众多 AFT 候选分布之一,可与 Log-Normal、Log-Logistic 等其他分布做 AIC 比较以选择最优形式。
4.4 总结
本研究系统性地完成了从数据准备、非参数估计、半参数回归到参数化建模的生存分析全流程,通过 Kaplan–Meier、Cox PH、Weibull AFT 三种方法的协同应用,量化了 Telco 数据集中按月签约互联网客户的生存模式与关键风险因子。研究的方法论框架可被推广至任何”事件发生时间”建模场景,包括但不限于客户保留、设备故障、贷款违约等。
]]>